Testing
AI-Locust 不是“多一个压测脚本”,而是一套可复用的性能测试资产
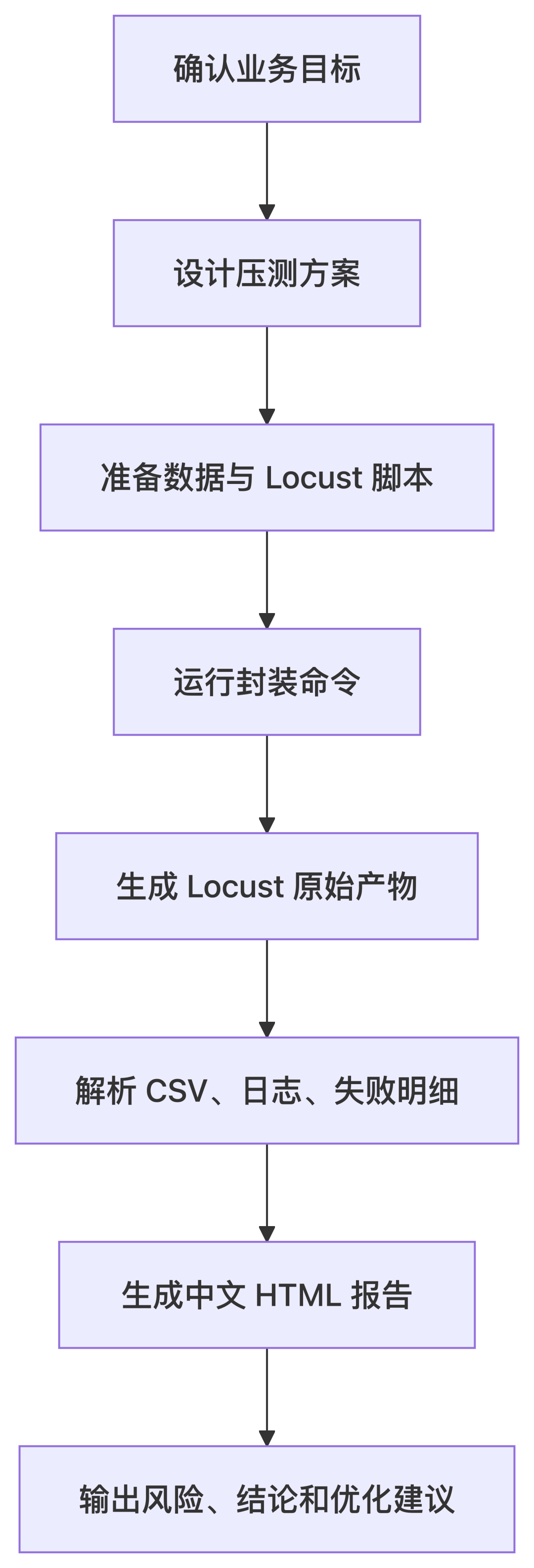
Locust 本身已经足够强,但很多团队的性能测试问题并不在于“能不能压”,而在于压测这件事能不能沉淀为一套可复用资产。AI-Locust 的价值就在这里:它不是替代 Locust,而是把方案设计、脚本开发、数据管理、原始报告、中文分析和结论建议串成一条完整链路。
为什么性能测试容易一次性化
很多团队做压测,往往是项目驱动:需求来了就跑一次,项目结束就散。脚本散在个人电脑里,数据散在表格里,结论散在聊天记录里。下一次再做,基本等于重来。
这套框架的思路是把压测工程化。脚本放 locustfiles/,数据放 data/,原始结果放 reports/raw/,二次分析放 reports/html/,日志单独存。每次执行自动生成时间戳目录,避免历史结果互相覆盖。
三类 Agent 的分工非常清楚
规划 Agent 先把业务背景、接口范围、并发模型、指标口径和退出条件问清楚;脚本开发 Agent 再把方案转成可执行脚本和数据模板;报告分析 Agent 读取 CSV、失败明细和日志,写出面向研发和测试的中文结论。
- 规划 Agent 负责把问题定义清楚。
- 脚本开发 Agent 负责把方案变成可执行资产。
- 报告分析 Agent 负责把原始指标变成可读结论。
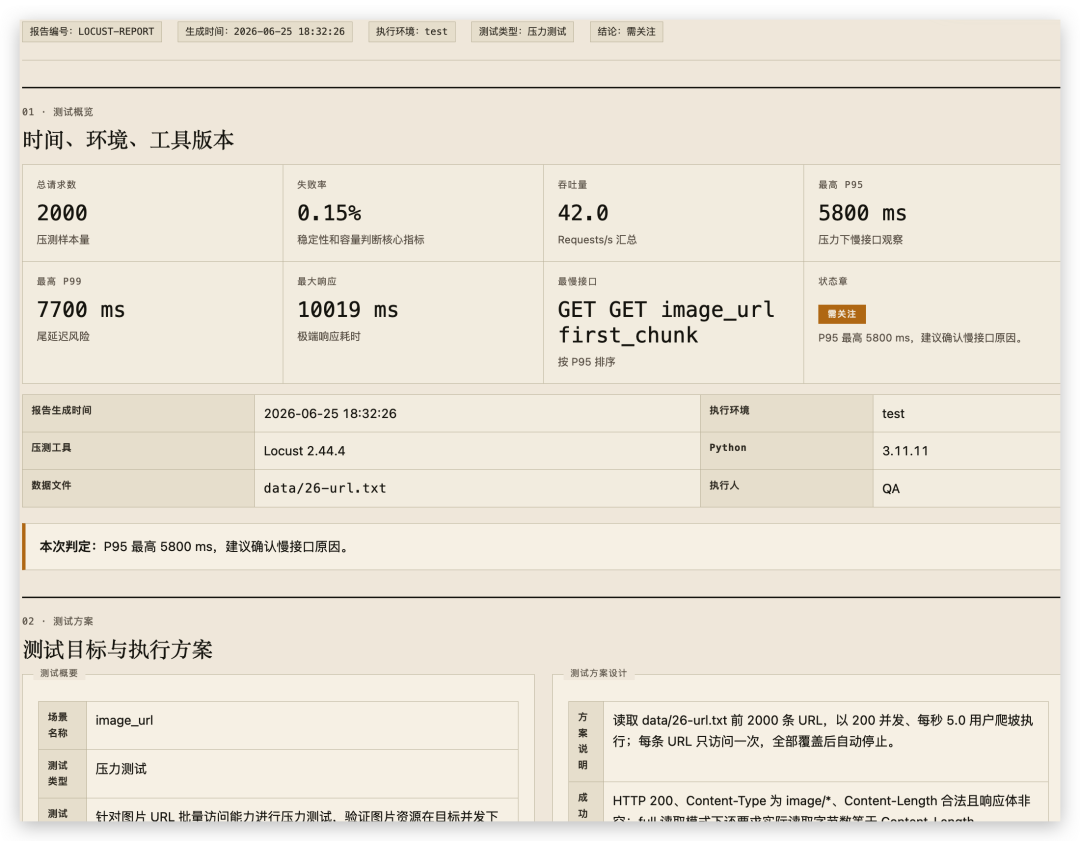
为什么这比单纯跑一次 Locust 更有价值
传统 Locust 命令只解决执行,不解决沉淀。AI-Locust 让每次测试都留下结构化资产:本次为什么压测、压了哪些接口、用了什么数据、失败在哪里、阈值是什么、下次如何复用。
这对测试团队尤其重要,因为性能测试最终不是“跑出一个数字”,而是形成可比较、可追踪、可复盘的工程记录。
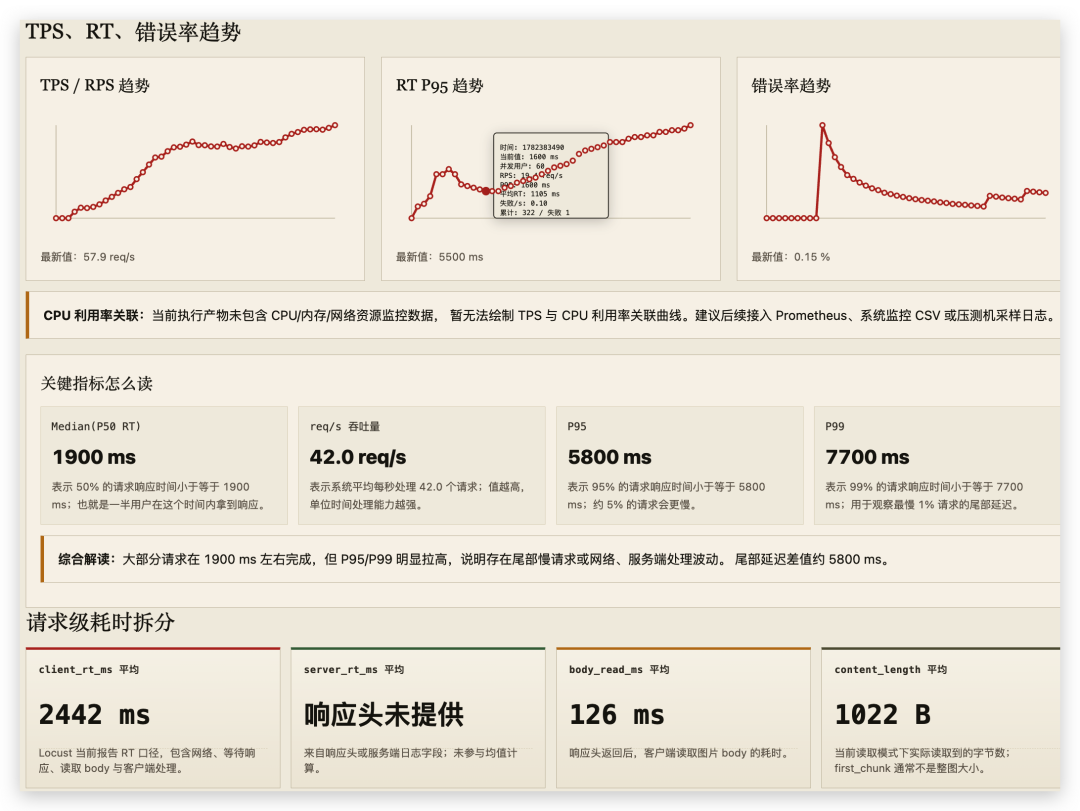
数据、脚本、报告分离的意义
把数据和脚本分离后,测试同学可以换数据不改脚本,研发可以审计数据来源,安全信息可以统一脱敏,报告还能对比历史基线。AI 适合组织语言和归纳结论,但事实来源仍然应该是 Locust CSV、失败 JSONL 和请求日志。
这点很关键:AI 不是替代证据,而是帮助你读证据。
适合什么场景
- 单接口上线前摸底。
- 核心链路并发验证。
- 缓存或重构前后效果对比。
- 图片、文件、CDN 链路压测。
- 长期稳定性测试和容量规划。
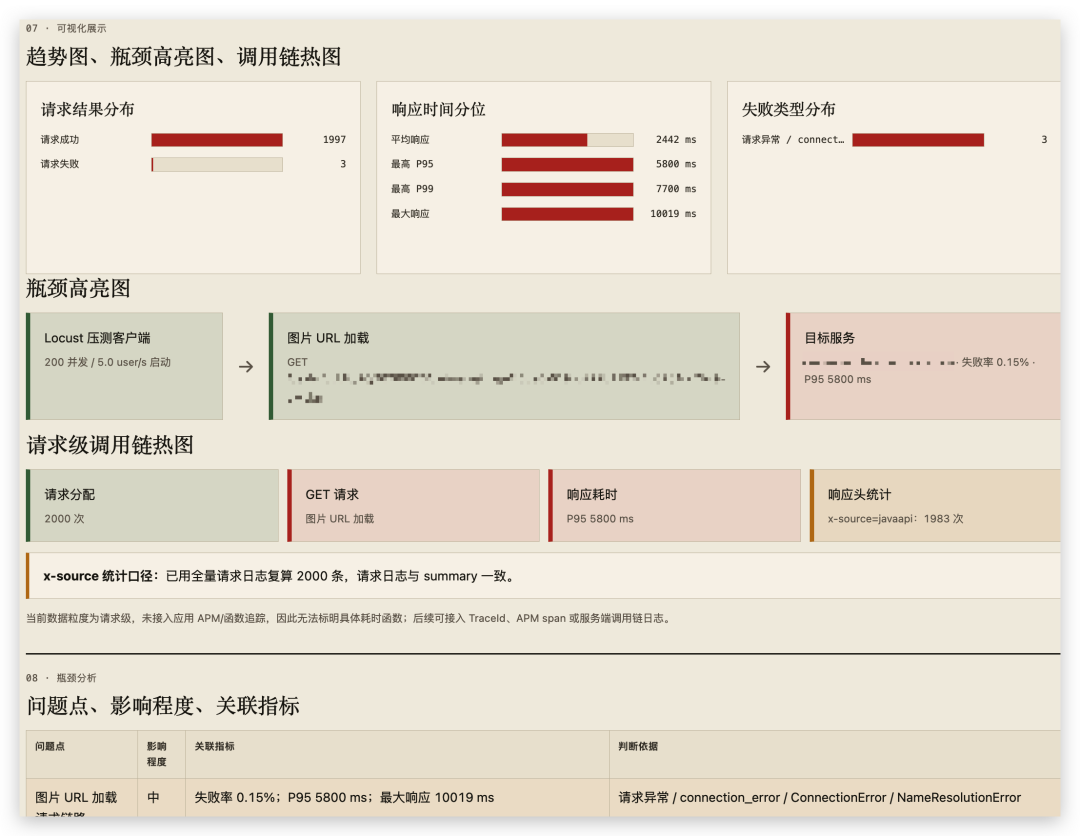
结论
AI-Locust 的真正贡献,不是让某一次压测更炫,而是把性能测试从一次性操作变成可复用资产。对于团队而言,这意味着更少的重复劳动、更容易的复盘,以及更稳定的性能基线。